
Introducing Enrich: Semantic Search for Unstructured Data
One API call to enrich your data with anything, perfectly connected with other AI primitives (Join, Split, Transform, Analyze, Evals). No custom pipelines, just build product with your source of truth. Instantly.
Semantic enrichment and intelligent data augmentation are how modern enterprises connect disparate sources, eliminate costly reconciliation, and automate unstructured data workflows at millisecond latency for their most critical operations.
Enrich is a first-class semantic search primitive that sits alongside our existing bem functions to power your critical data operations. This is next-generation data enrichment built for the reality of unstructured data—where accuracy is measured through vector similarity scores, guaranteed through semantic understanding, and scalable from messy PDFs to clean JSON in seconds.
What Is Enrich?
Enrich is a semantic search function that augments your transformed JSON data with relevant information from collections through vector-based similarity matching. Transform messy unstructured data, then instantly enrich it with context from your product catalogs, customer databases, inventory systems, or any structured collection—all without exact matches, rigid schemas, or brittle key-value lookups.
How It Works:
- Ingest unstructured data through any bem function (transform, analyze, or workflows)
- Extract and vectorize fields from your JSON output
- Search collections semantically using meaning, not exact text matches
- Inject enriched results back into your data automatically
Each enrichment step maintains precision through similarity scores. Search results flow through your pipeline. Matches are semantic and intelligent. The entire process becomes a single, composable function that chains with transforms, routes, and workflows.
1// Empty Code Block
Execute your enrichment with one API call. Bem handles vectorization, semantic search, confidence scoring, and result injection automatically.
Why This Changes All Things Unstructured Extraction
Semantic Understanding, Not Exact Matching
Traditional data enrichment breaks when your unstructured input doesn't perfectly match your structured lookup. Customer writes "wireless earbuds"? Your SKU database says "Bluetooth Audio Devices." Conventional joins return nothing. Enrich returns the right products.
But when you need exact matches, you get exact matches. Enrich supports both semantic search for fuzzy matching and exact keyword matching when precision is required. Search by SKU codes, invoice numbers, or any field where exact values matter—all in the same enrichment step.
Real-world impact: E-commerce teams processing customer inquiries can match fuzzy descriptions to exact SKU codes, even with typos, abbreviations, or regional terminology. No more failed lookups. No more manual reconciliation.
Latency That Scales
Speed matters. Processing happens at production-ready latency—sub-second semantic search even at scale.
- Process 100 records: ~2 seconds
- Process 10,000 records: ~15 seconds
- Process 1M records: minutes, not hours
Impact: If your data team spends 10 hours/week manually matching invoice line items to product catalogs, that's 520 hours/year. Enrich automates this completely.
Works With Messy Reality
Your data isn't clean. Your PDFs have OCR errors. Your customer emails use slang. Your invoices abbreviate product names. Traditional enrichment fails here—semantic search thrives.
Enrich handles:
- OCR artifacts from scanned documents
- Typos and variations in product descriptions
- Multi-language inputs with semantic understanding
- Incomplete data through fuzzy matching
- Domain-specific terminology through collection-specific embeddings
Composable Infrastructure
Enrich isn't a standalone tool—it's a primitive that composes with every bem function:
Transform → Enrich → Analyze:
Customer support ticket → Extract product complaint → Enrich with product specs & warranty info → Analyze sentiment & urgency for prioritization
Transform → Enrich → Route:
Messy invoice PDF → Extract line items → Match to SKU catalog → Route to billing system
Example: A customer submits a support ticket saying "my bluetooth speaker won't charge anymore." Transform extracts the product reference, Enrich matches it to your product catalog (finding it's a "Portable Wireless Audio Device - Model BT-2847"), then Analyze cross-references warranty status, common issues, and solution success rates to automatically route to the right support tier with full context.
This composability means you build complete data operations, not just enrichment steps.
Real-World Use Cases
E-Commerce: SKU Matching at Scale
The Challenge:
1// Empty Code Block
Impact:
- Before: 3 minutes per return for manual SKU lookup × 500 returns/day = 25 hours/day
- After: Automated matching with 95% accuracy
- Value: 25 hours/day of human time returned to higher-value work
Healthcare: Clinical Code Matching
The Challenge:
With Enrich:
1// Empty Code Block
Input: "Patient presents with acute upper respiratory infection, cough, fever"
Impact:
- 80% auto-coded with human review for edge cases only
- Processing time cut from 15 minutes to 2 minutes per document
- Coders focus on complex cases requiring judgment
Supply Chain: Invoice Reconciliation
The Challenge:
Transform → Enrich Pipeline:
1// Empty Code Block
Impact:
- Manual reconciliation: 15 min per invoice × 200 invoices/day = 50 hours/day
- Automated with Enrich: 2 minutes human review per invoice
- Time savings: 93% reduction in reconciliation time
Financial Services: Document Classification & Data Extraction
The Challenge:
Workflow Integration:
1// Empty Code Block
The enrich step matches extracted employer names, addresses, and account numbers to internal databases semantically—handling variations in company names ("ABC Corp" vs "ABC Corporation") or formatting differences.
Impact:
- Manual processing: 45 minutes per application
- Automated workflow: 5 minutes human review
- Processing capacity: 10x increase with same headcount
Insurance: Claims Matching
The Challenge:
Enrich Configuration:
1// Empty Code Block
Impact:
- Fraud detection improvement: 23% increase in flagged suspicious claims
- Claims processing speed: 40% faster adjudication
Additional Example High-Volume Use Cases
Legal: Contract Clause Matching - Match contract clauses to standard templates and regulatory requirements. Enrich NDA terms with GDPR compliance language.
Real Estate: Property Matching - Match free-text property descriptions from listings to MLS data, comparable sales, and zoning records.
Logistics: Shipment Classification - Match shipping descriptions to HS codes, hazmat classifications, and carrier restrictions.
Customer Support: Ticket Enrichment - Match support tickets to knowledge base articles, past resolutions, and customer history.
HR: Resume Matching - Match resume text to job requirements, skills databases, and past successful hires.
Why Data Operations Are Changing
80-90% of enterprise data is unstructured, but only a fraction is utilized for analytics or operations. Data teams spend 60% of their time on data quality and integration issues. Manual data matching costs enterprises an average of $15M annually in lost productivity.
Vector databases and semantic search are seeing 300% YoY growth in enterprise adoption. The tools exist, but most teams still build custom pipelines, manage embeddings manually, and maintain brittle matching logic.
Context powers AI systems. Large language models require grounded, enriched data to avoid hallucination. Retrieval-Augmented Generation (RAG) architectures are becoming standard, and semantic search is the bridge between unstructured inputs and structured knowledge bases.
RAG at scale: Your LLM can query enriched data that's already matched, validated, and contextualized—not raw, unreliable documents. Enrich provides the enrichment layer that makes production RAG systems actually work.
Latency matters. Real-time applications can't wait for batch enrichment jobs. Customer-facing AI needs sub-second response times. Internal operations need same-day processing, not weekly ETL runs. Companies that enrich data in real-time respond to customers 10x faster than competitors stuck in batch processing cycles.
Auditability isn't optional. Financial services, healthcare, and government contractors face strict data lineage and audit requirements. Manual enrichment creates gaps in documentation. Automated enrichment with confidence scores provides the audit trail regulators demand.
Enrich provides similarity scores for every match, source collection versioning, timestamp and user tracking, and full data lineage from unstructured input to enriched output.
Built for Production Operations
Insurance claims. Loan underwriting. Medical coding. Supply chain reconciliation.
Operations where accuracy is mandatory. Where audit trails are required. Where scale cannot compromise quality.
Enrich makes these possible because:
- Semantic search is independently measurable through similarity scores
- Collections are explicitly versioned for reproducibility
- Confidence thresholds are configurable per use case
- Results are injected with full linearity to source documents
Observable and Trainable
Every enrichment reports:
- Similarity scores for each match
- Source collection and version
- Query time and processing latency
- Confidence distribution across results
Use built-in evals to measure enrichment quality. Fine-tune embeddings with 1-click training. Monitor accuracy over time as your collections evolve.
The Gap Between Teams
Without Semantic Enrichment:
- Spend 15+ hours/week on manual data matching and reconciliation
- Lose 30-40% accuracy due to human error and fatigue
- Scale linearly—more data requires more people
- Create technical debt through brittle exact-match scripts
- Miss opportunities hidden in unstructured data
With Enrich:
- Automate 80-95% of matching workflows
- Achieve 90%+ accuracy through semantic understanding
- Scale exponentially—same team handles 10x the volume
- Build composable, maintainable data operations
- Unlock value from previously unusable unstructured data
How Enrich Compares
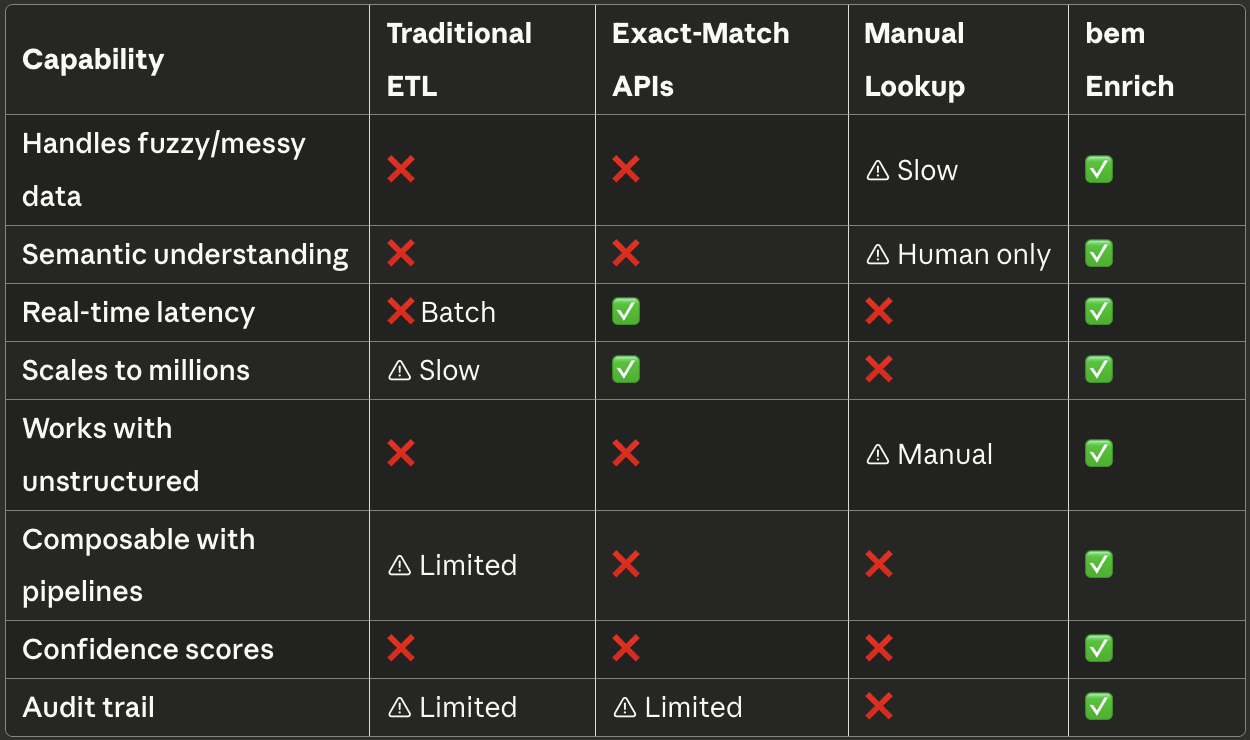
Getting Started with Enrich
1. Upload Your Collection
Create a collection from any structured data source—CSVs, database exports, API responses:
1// Empty Code Block
bem automatically generates embeddings for semantic search.
2. Create Your Enrich Function
Define what to extract, where to search, and where to inject results:
1// Empty Code Block
3. Chain with Transform
Build end-to-end pipelines:
1// Empty Code Block
4. Monitor and Iterate
Use built-in observability to measure enrichment quality:
- Review similarity score distributions
- Identify low-confidence matches for human review
- Fine-tune embeddings based on corrections
- A/B test different similarity thresholds
Start Enriching Today
- Read the Enrich docs
- Book a demo and our team will build an enrichment pipeline for you
- Try Enrich for free
Stop matching data manually. Start enriching semantically.


Ready to see it in action?
Talk to our team to walk through how Bem can work inside your stack.
Talk to the team